豪俊斐波那契 / 基于CUDA的万亿斐波那契数子串寻踪
��初学 CUDA,忍不住上手试验一番并行优化。直入正题,任务目标为:
寻找第
这个问题似乎有一个数学上的算法,暂时不太了解,因此仅做第一次写 CUDA 的练习。初学难免犯错,如有错误请指出。下述算法如果未特殊说明,默认在模意义下讨论。
斐波那契数列的并行递推
首先是构建搜索过程,如何并行化搜索呢?斐波那契数的计算是串行的,即
那还有什么办法呢?很快就能想到基于递推矩阵的方法。我们有
由此递推,容易得到第
令
然而还没结束。注意到计算
快速幂算法的并行优化
继续优化!注意到在 int128 的限制下,每一个线程都要对它们所负责的数字进行 128 次矩阵乘法——还是稍多,经过考虑,我们可以从进制的角度优化一下这个算法。
回顾二进制矩阵幂的过程,主要由两步构成:
- 预处理出
, , ,..., 这些幂矩阵,每一个幂矩阵都可以由前一个平方得到,这里一共需要 次矩阵乘法,储存 个矩阵 - 每个并行线程对于给定数字
,将 写成 128 位的二进制,如果第 位为 ,则累乘一个 ,直到最后累乘得到 ,这里一共需要至多 128 次矩阵乘法
如果我们不拘泥于二进制呢?例如,将基数
- 预处理出
, , ,..., 这些幂矩阵,每一个幂矩阵都可以由前一个平方得到,这里一共需要 次矩阵乘法,储存 个矩阵 - 对于每个
矩阵,继续预处理出 、 、...、 这些矩阵,每个矩阵都可以由前一个矩阵乘上 得到,这里一共需要 次矩阵乘法,储存同样多个矩阵 - 每个并行线程对于给定数字
,将 写成对应位的 进制,如果第 位数字为 ,则累乘一个 ,直到最后累乘得到 ,这里一共需要至多 次矩阵乘法
这里多了一步,也就是将这些幂矩阵的“中间倍数”结果也求了出来。可以看到,当
那么
- 预处理第一阶段,需要
次矩阵乘法 - 预处理第二阶段,需要
次矩阵乘法 - 并行线程,每个线程至多
次乘法
非常好!通过将一些计算量下放到主机端预处理,每个 CUDA 线程的计算压力都从 128 次矩阵乘法下降到 16 次,美哉。
相关代码如下
主机端
// 计算 Fibonacci 矩阵的 BASE 的幂次方与倍数,结果存储在动态分配的数组中
__host__ Mat2x2** fibo_mat_Bpows() {
/*
计算并返回 Fibonacci 矩阵的 BASE 的幂次方与倍数矩阵
例如,对于 BASE = 4。返回矩阵形如
I 1 * F^(4 ^ 0) 2 * F^(4 ^ 0) 3 * F^(4 ^ 0)
I 1 * F^(4 ^ 1) 2 * F^(4 ^ 1) 3 * F^(4 ^ 1)
I 1 * F^(4 ^ 2) 2 * F^(4 ^ 2) 3 * F^(4 ^ 2)
...
I 1 * F^(4 ^ MAX_MATS_NUM) 2 * F^(4 ^ MAX_MATS_NUM) 3 * F^(4 ^ MAX_MATS_NUM)
其中 F 是 Fibonacci 矩阵
*/
// 分配连续内存以便于GPU传输
Mat2x2 *flat_mats = new Mat2x2[(MAX_MATS_NUM + 1) * BASE];
Mat2x2 **mats = new Mat2x2*[MAX_MATS_NUM + 1];
// 设置指针数组指向连续内存的相应位置
for (int row = 0; row <= MAX_MATS_NUM; row++) {
mats[row] = &flat_mats[row * BASE];
mats[row][0] = {1, 0, 0, 1};
if (row == 0) {
mats[row][1] = {1, 1, 1, 0}; // F^1 = Fibonacci矩阵
} else {
// 计算 F^(BASE^row) = (F^(BASE^(row-1)))^BASE
Mat2x2 base_power = mats[row - 1][1]; // F^(BASE^(row-1))
mats[row][1] = base_power;
for (int i = 1; i < BASE; i++) {
mats[row][1] = multiply(mats[row][1], base_power, MOD);
}
}
// 计算 col * F^(BASE^row)
for (int col = 2; col < BASE; col++) {
mats[row][col] = multiply(mats[row][col - 1], mats[row][1], MOD);
}
}
return mats;
}
设备端
// 找到 start_idx 对应 BASE 进制表示,并得到对应矩阵的模乘,即 F(start_idx)
const Mat2x2 Identity = {1, 0, 0, 1};
Mat2x2 bound_fib_mat = {1, 0, 0, 1}; // 初始为单位矩阵 I
Mat2x2 fibo_recursion = {1, 1, 1, 0};
// 将 start_idx 按 BASE 进制分解并计算对应的矩阵乘积
uint128 temp_idx = start_idx;
for (int pos = 0; pos <= MAX_MATS_NUM && temp_idx > 0; pos++) {
unsigned int digit = temp_idx & (BASE - 1); // 等价于 temp_idx % BASE
// 避免分支发散,使用三元运算符
// digit 为 0,相当于乘以单位矩阵,不改变结果
const Mat2x2& mat_to_multiply = (digit > 0) ? mats[pos][digit] : Identity;
bound_fib_mat = multiply(bound_fib_mat, mat_to_multiply, MOD);
temp_idx >>= W_BASE; // 下一个幂次的处理
}
子串检查算法
因为在 GPU 中执行分支会导致分支发散,导致线程空转严重,因此子串检查不能采取一般的 KMP 等算法的思路,而要用顺序性较好、分支较少的检查方式。
这里的检查就较为简省,每次对待检数字进行检查时,都会右移一个十进制位,然后看看除去对应位的
// 检查 N 是否包含 TARGET_NUMBER 作为十进制子串
__device__ bool contains_decimal_substring(uint128 N) {
if (N < TARGET_NUMBER) {
return false;
}
uint128 temp_N = N;
const int MAX_CHECKS = 40 - M; // uint128 的十进制最大有 39 位
for (int i = 0; i < MAX_CHECKS; ++i) {
uint128 remainder = temp_N % SUB_NUMBER_10POW;
if (remainder == TARGET_NUMBER) {
return true;
}
temp_N /= 10;
if (temp_N < TARGET_NUMBER) {
break;
}
}
return false;
}
也许比较耗时?不过感觉也差不多优化到较好了... 可能有些数学或工程的奇技淫巧吧...
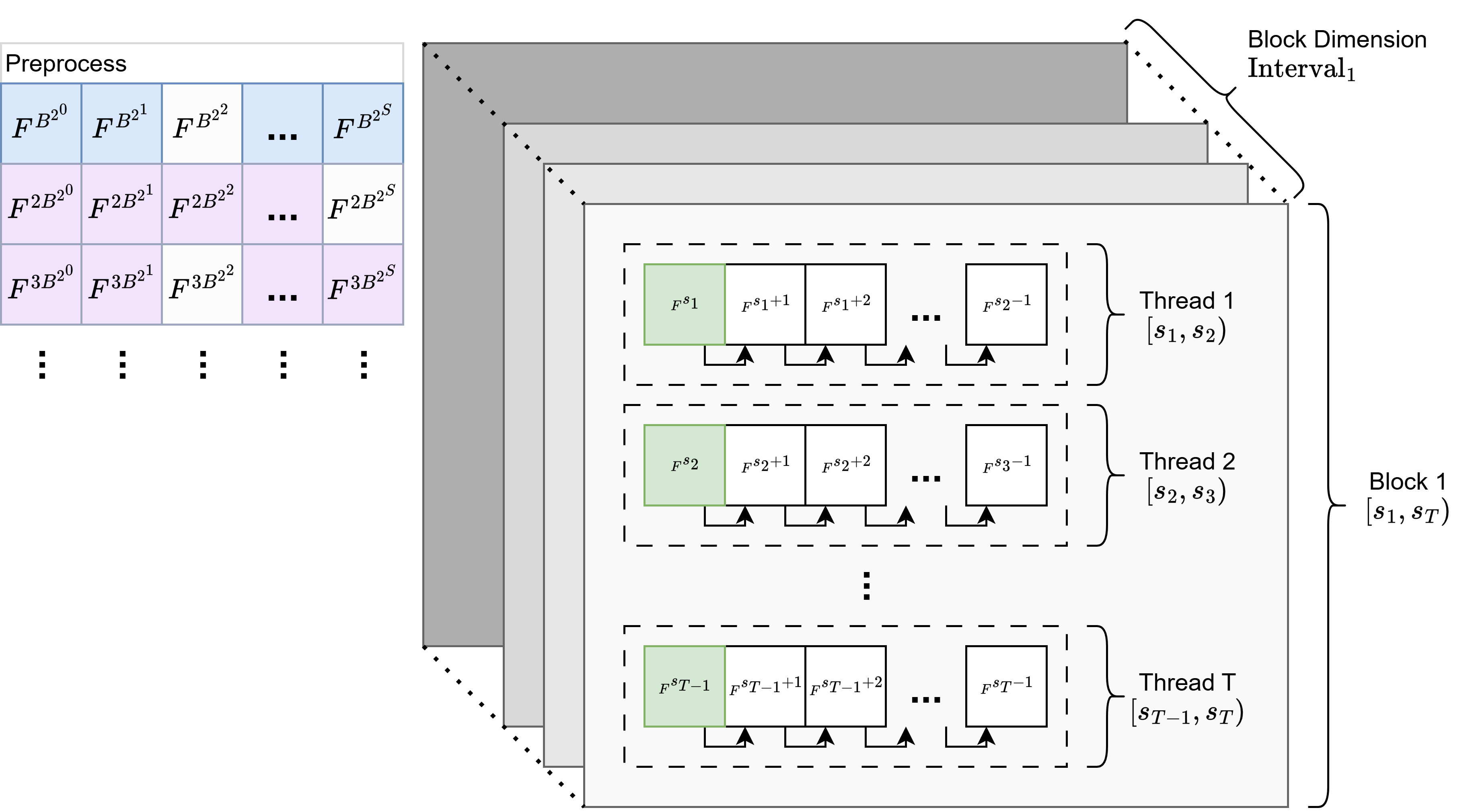
分块策略
因为最终要丢到 GPU 上算的嘛,因此如何分块也是比较重要的。这里分块的方式也比较简单,详见下图
一嘴数学
斐波那契数列的模数其实是有周期性的,其被称为匹萨诺周期1
运行测试
CMake 后运行,指定数字进行测试,每秒约有二十亿个斐波那契数被搜索。
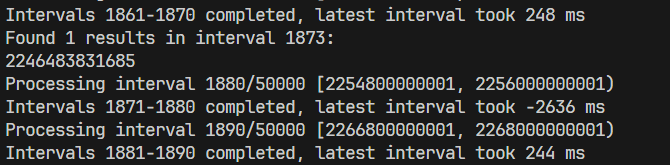
成功确认: